신경망을 사용하여 특징 추출하기
AudioIdentify에서 사용되는 네트워크는 소리의 인식, 그리고 녹음으로의 특징 추출에도 사용할 수 있습니다. 이것을 사용하면 유사도와 거리를 계산할 수 있는 의미적으로 중요한 공간에 임의의 신호를 포함할 수 있습니다.
Wolfram Neural Net Repository에서 AudioIdentify에 사용되는 네트워크를 얻습니다.
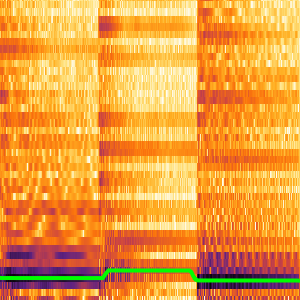
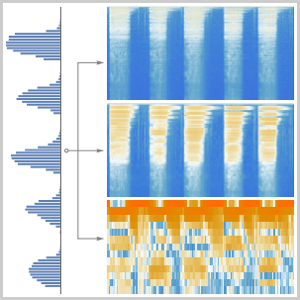
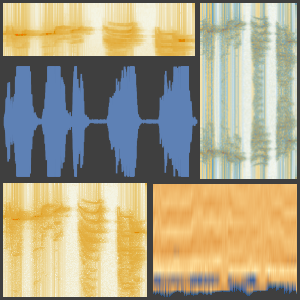
신호를 고정 크기의 청크로 나누고, 이 네트워크를 각 청크의 멜 스펙트로그램에 적용함으로써 네트워크의 핵심을 추출합니다. 여기에는 NetExtract을 사용합니다.
분류 작업을 담당하는 지난 몇 층을 삭제하고, 결과의 네트워크를 원래의 NetChain에 다시 삽입합니다. 이 넷은 각 오디오 입력에 대해서 고정 크기의 의미적으로 중요한 벡터를 생성합니다.
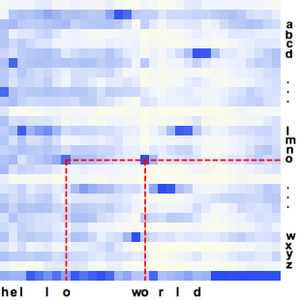
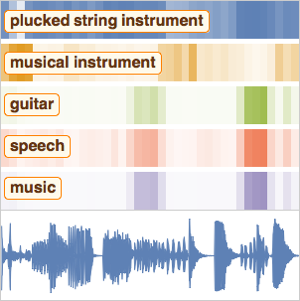
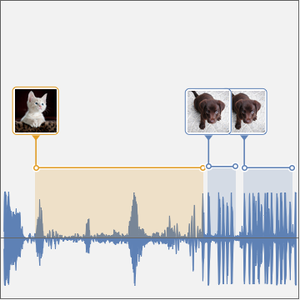
단독 음성 녹음에 대한 특징을 시각화합니다.
단독 음성 녹음에 대한 특징을 시각화합니다.
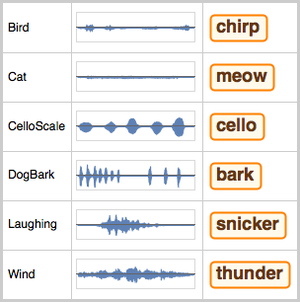
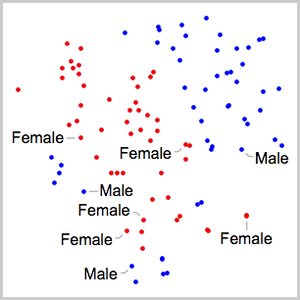
저장소에 있는 다른 훈련된 특징 감지기를 사용합니다.