효율적인 오디오 인코더
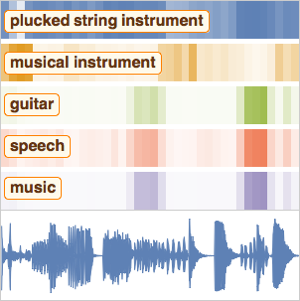
대규모 훈련을 실천하기 위해 데이터를 네트워크에 효율적으로 가져오는 방법이 필요합니다. 음성 NetEncoder는 이런 경우에 필요한 효율적인 낮은 수준의 기능을 제공합니다.
Wolfram Data Repository에서 사용 가능한 데이터 집합을 사용하여 인코더의 효율성을 측정할 수 있습니다. 이 데이터 집합은 상대적으로 작은 것으로 (Google의 Speech Commands 데이터 집합의 부분 집합), 10,000건의 짧은 훈련 예를 포함합니다.
하나의 예를 선택합니다.
음성 인코더는 정규화, 리샘플링, 자르기/충전 등 온라인에서의 전처리 작업을 지원합니다. 정규화를 실시하는 "Audio" 인코더에서 걸리는 시간과 AudioNormalize의 간단한 호출에 걸리는 시간을 비교합니다.
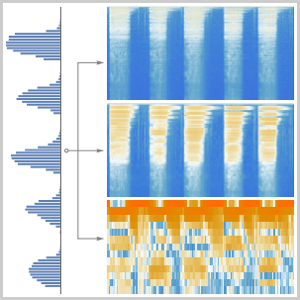
데이터 집합 전체에 대해 "AudioSpectrogram" 인코더에서 시간과 동일한 시스템 함수에 걸리는 시간을 비교합니다.
전체 Wolfram 언어 입력 표시하기
아웃 오브 코어 Audio 객체의 집합에 대해 "AudioSpectrogram" 인코더에서 시간과 동일한 시스템 함수에 걸리는 시간을 비교합니다.
전체 Wolfram 언어 입력 표시하기
인코어 Audio 객체의 데이터 집합을 최상위 코드로 인코딩하는 데 걸리는 시간과 데이터 크기의 함수로 NetEncoder로 인코딩하는 데 걸리는 시간을 비교합니다.
아웃 오브 코어 오디오 파일을 최상위 코드로 인코딩하는 데 걸리는 시간과 데이터 집합 크기의 함수로 NetEncoder로 인코딩하는 데 걸리는 시간을 비교합니다.