음성 식별 네트워크를 사용한 신호 조사하기
AudioIdentify에서 사용되는 네트워크는 다른 음성 분석 작업을 위한 매우 강력한 도구입니다. 아래의 예는 이러한 네트워크를 변경하여 시간이 분해된 결과로서 시간이 지남에 따른 확률을 얻습니다.
Wolfram Neural Net Repository에서 네트워크를 가져옵니다.
Audio 개체에 네트워크를 적용합니다.
이 네트워크는 AudioSet 데이터 집합에서 훈련되어 있습니다. 이 데이터 집합은 각 음성 신호에 녹음 안에 존재하는 소리의 클래스와 자료의 주석이 붙어있습니다.
그 결과, 출력의 각 클래스의 확률은 상호 배타적이 되지 않습니다.
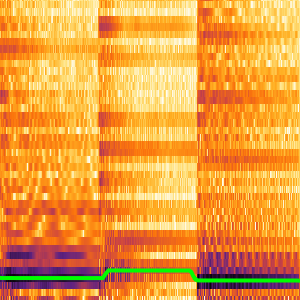
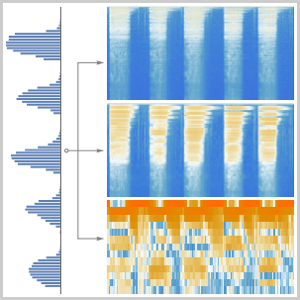
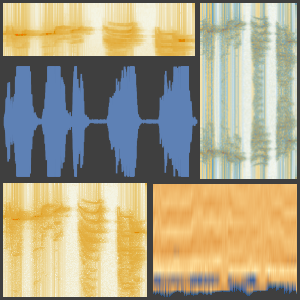
네트워크의 핵심은 입력 신호의 멜 스펙트로그램의 관련된 요소를 묶어 내는 능력인 정해진 크기의 청크를 가지고 NetMapOperator를 사용하여 중복 청크에 매핑됩니다.
이것이 핵심 네트워크입니다.
신호의 예에서 결과를 계산할 수 있습니다.
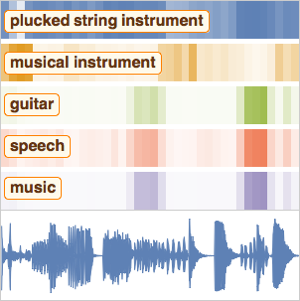
그 결과는 모든 청크에서 계산된 각 클래스에 대한 독립적인 확률의 열입니다. 신호에 존재하는 모든 클래스를 찾기 때문에 평균이 아니라 시간의 흐름에 따른 최대값을 가집니다.
조금 더 조작해보면 각 청크에 대한 클래스의 확률을 출력하는 네트워크를 만들 수 있습니다.
WebAudioSearch를 사용하면 악기의 소리를 모으고 서로 결합할 수 있습니다.
네트워크의 결과를 계산하는 함수를 정의하고 전체 시퀀스에서 n개의 가장 가능성이 있는 클래스를 보고 시간이 지남에 따라 해당 확률을 출력할 수 있습니다.
파형을 진화할 확률이 가장 높은 10개 클래스의 확률 (및 시간에 따른 진화)과 함께 시각화합니다.