음성 데이터 집합 분류하기
강력한 음성 분류자의 생성은 모든 고급 기계 학습 함수에 존재하는 자동 특징 추출로 수월해 졌습니다. 이 예는 Environmental Sound Classification (ESC-50)의 표준 데이터 집합을 자동으로 분류합니다.
데이터 집합을 다운로드 합니다.
전체 Wolfram 언어 입력 표시하기
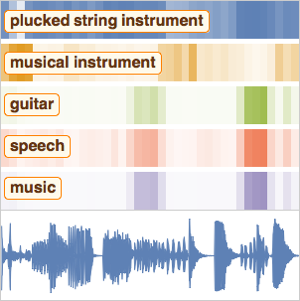
메타 데이터를 가져옵니다. 데이터 집합은 2000개의 환경 음성 녹음의 라벨이 붙은 데이터 집합입니다. 각 파일은 5초짜리 음성 녹음에서 50종류의 의미 클래스로 정리하고 있습니다.
전체 Wolfram 언어 입력 표시하기
메타 데이터에서 샘플을 조사합니다.
데이터 집합을 훈련 데이터와 검증 데이터로 나눕니다.
Classify를 사용하여 ClassifierFunction을 훈련 데이터로 훈련합니다. 전처리, 특징 추출, 분류 알고리즘이 모두 입력 데이터에 따라 자동으로 선택됩니다.
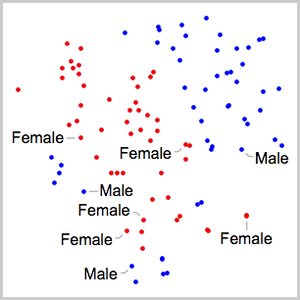
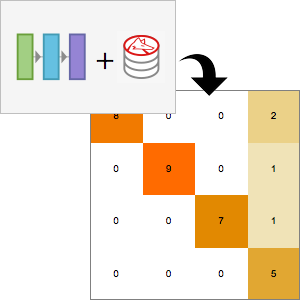
검증 데이터의 정답율을 계산하고 혼동 행렬을 플롯합니다. 명시적인 사용자 입력이 없는데도 불구하고, 분류의 정답율은 90%를 넘습니다.