넷 인코더 데이터 확장하기
내장된 음성 NetEncoder는 특징을 계산하기 전에 온라인에서 다양한 데이터 확장을 수행할 수 있습니다. 데이터 확장은 훈련된 모델을 지나치게 맞추어 초과하지 않도록 더 강력하게 하거나, 데이터의 일부 특정 부분에 불변성을 추가하기 위해 데이터 집합의 유효한 크기를 늘리기에 편리합니다.
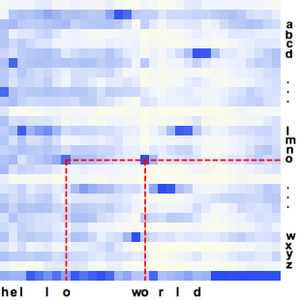
검증 신호를 생성하고 플롯합니다.
± ![]() 의 균일 분포에서 무작위로 샘플링한 양에서 각 훈련 예를 잘라내 인코더를 작성합니다. 이것은 소리 이벤트의 지역성에 대한 모델의 불변성을 높이는 데 도움이 됩니다.
의 균일 분포에서 무작위로 샘플링한 양에서 각 훈련 예를 잘라내 인코더를 작성합니다. 이것은 소리 이벤트의 지역성에 대한 모델의 불변성을 높이는 데 도움이 됩니다.
균일 분포에서 무작위로 샘플링한 상수 계수를 각 예에 걸쳐 입력의 진폭을 임의로 조정하는 인코더를 작성합니다.
지정된 모델(여기에서는 정현파)의 노이즈를 각 예에 추가하는 인코더를 작성합니다. 소음 수준은 0부터 0.1까지의 균일 분포에서 샘플링된 것을 사용합니다.
무작위로 샘플링한 혼합 레벨을 사용하여 각 훈련 예를 다른 신호로 접어 넣는 인코더를 만듭니다. 이것은 예를 들어 반향을 추가하는 등의 다양한 녹음 환경의 영향 시뮬레이션에 도움이 됩니다.
"AudioMelSpectrogram" 또는 "AudioMFCC" 중 하나의 인코더를 사용하는 경우, 파워 스펙트럼의 요약에 사용되는 필터 뱅크의 중심 간격은 인간의 발성의 목소리 길이 차이의 영향의 시뮬레이션을 위해 무작위로 구부릴 수 있습니다. "VTLP" 확장을 사용하여 인코더를 작성합니다. 왜곡 계수는 0.5부터 2까지의 균일 분포에서 무작위로 샘플링 합니다.