영어를 모델링하기 위해 네트워크 훈련하기
이 예는 순환 신경망을 훈련하여 영어 텍스트를 생성하는 방법을 보여줍니다.
우선 두 소설에서 따온 25자의 훈련 예를 300,000 예로 만듭니다.
분류 문제의 형식으로 데이터를 샘플링합니다. 문자열이 주어지면 다음 문자를 예측합니다.
텍스트에 포함된 모든 문자 목록을 얻습니다.
문자열 전체를 한 번에 예측하는 네트워크를 구축합니다. LinearLayer 앞에 SequenceLastLayer를 사용하는 것이 아니라 NetMapOperator가 사용되고 있는 점에 유의합니다. 결과적으로, 이 네트워크는 단순히 문자열의 마지막 문자를 예측하는 것이 아니라 각 문자에 대해 문자열의 다음 문자를 동시에 예측합니다.
이제 대상이 되는 문장을 가지고 이를 네트워크에 "스테거드" 형식으로 제시하는 "교사 강제" 네트워크를 구축합니다. 즉, 길이 26의 문장에 대해 네트워크가 2부터 26까지의 문자에 대한 예측을 할 수 있도록 1부터 25까지의 문자를 제시합니다. 예측은 손실을 가져 오기 위하여, CrossEntropyLossLayer를 통해 실제의 문자와 비교됩니다.
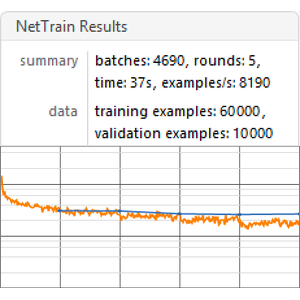
이 네트워크를 원래 데이터의 입력 열에 대해 훈련합니다.
결과에서 예측 체인을 추출합니다.
이제 단일 문자의 예측 체인을 구축합니다.
예측자를 검증합니다.
효율적으로 텍스트를 생성하기 위해 NetStateObject를 만듭니다.
네트워크에서 배운 분포에 따라 200자를 생성합니다. 생성된 텍스트는 영어와 유사하지만 작은 코퍼스 (약 2백만 자)에 대해 훈련 되었기 때문에 많은 단어가 영어가 아닙니다.
약 10억 자로 훈련된 같은 네트워크와 비교합니다.