강화 학습 환경에서 에이전트 훈련하기
이 예는 REINFORCE 법 (Williams, 1992)을 사용하여 "Simulated Cart Pole" 환경에서 보상을 극대화하기 위한 간단한 신경망의 훈련 방법을 보여줍니다. 카트 폴 환경은 마찰이 없는 1차원 경로를 따라 이동하는 카트와 힌지(즉 역 진자)로 카트에 장착된 가중 막대기로 구성됩니다. 카트는 개입이 없으면 막대기가 쓰러져 버리는 초기 속도를 가지고 있습니다. 에이전트의 목표는 가능한 한 봉을 오랫동안 똑바로 세운 상태를 유지하는 것입니다. 이것은 두 가지 가능한 동작 (왼쪽으로 움직이는지, 오른쪽으로 움직이는지)의 어느 쪽을 실시할 것인지를 학습함으로써 달성됩니다.
초기 상태의 환경을 로드하고 렌더링합니다.
카트를 왼쪽으로 이동하는지 또는 오른쪽으로 이동하는지를 결정하는 방안을 학습하는 간단한 네트워크를 정의합니다.
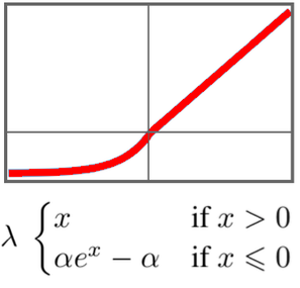
방안 기울기 학습의 손실 함수를 정의합니다.
네트워크 훈련 데이터를 샘플링하는 생성기 함수를 정의합니다.
전체 Wolfram 언어 입력 표시하기
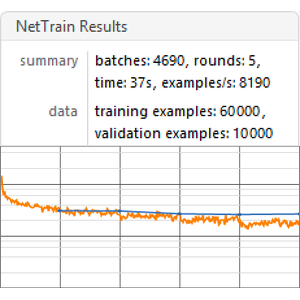
평균 할인 보수를 측정하여 정책망을 훈련합니다.
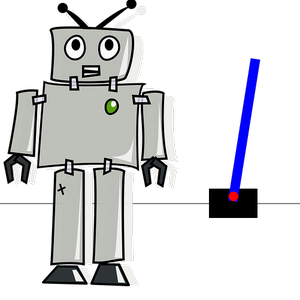
훈련된 정책망을 사용하여 환경을 애니메이션화 (아래 이미지를 클릭하면 애니메이션을 볼 수 있습니다)합니다. 막대는 똑바로 서 있는 상태인 것에 주목합니다.
이와 이 환경에서 임의로 움직이는 에이전트를 비교합니다(아래 이미지를 클릭하면 애니메이션을 볼 수 있습니다).