자기 정규화 신경망 훈련하기
역사적으로 몇 층 이상의 완전히 연결된 신경망의 훈련은 매우 어려웠습니다. 깊은 네트워크는 모두 합성곱층 또는 순환층 같은 가중치 공유를 사용했습니다. 또한 신경망은 인식 이외의 작업에서 (랜덤 포레스트 등) 기존의 기계 학습 방법과 경쟁하는데 어려움을 겪었습니다. 2017년에 출시된 자기 정규화 신경망 (SNN)은 깊고 완전히 연결된 네트워크의 훈련을 허용하는 최초의 신경망 구조이며, 일반적으로 클래스 및 숫자 행의 구조화된 데이터에 대해 기존 메소드에 대항할 수 있는 최초의 구조이기도 합니다. 이 예는 이러한 네트워크의 구축과 훈련 방법을 보여줍니다.
SNN은 매우 간단한 클래스의 네트워크입니다. 정규화를 위해 선형 층, 요소 단위의 비선형성 , 수정된 "Dropout" 버전만 사용합니다. 7개의 선형층으로 구성된 SNN 분류자를 구축합니다.
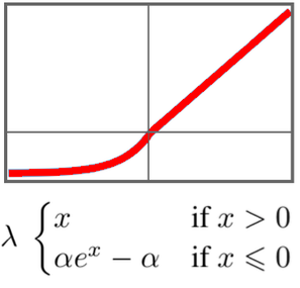
이 네트워크의 중요한 요소는 "SELU" (Scaled Exponential Linear Unit) 비선형성입니다. "SELU" 비선형성은 데이터를 표준화된 상태로 유지하고 경사가 너무 커지거나 너무 작아지지 않도록 하는 특수성을 갖습니다.
이 네트워크를 UCI 문자 분류 작업에서 훈련합니다.
자기 정규화 네트워크는 입력 데이터의 평균이 0이고 분산이 1이라고 가정합니다. 훈련 데이터와 검증 데이터를 표준화합니다.
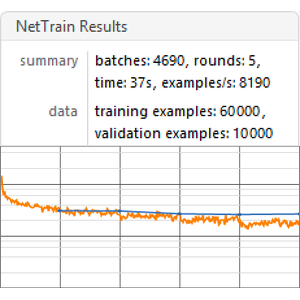
이 네트워크를 150 라운드 훈련하고 데이터의 5%는 검증을 위해 남겨 둡니다.
이 네트워크를 새로운 예에 사용합니다.
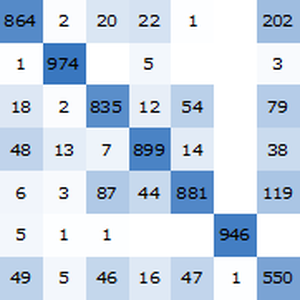
표준화된 검증 집합에 대한 훈련된 네트워크의 정확도를 얻습니다.
자기 정규화 네트워크의 정확도 (약 96.4%)는 기존의 기계 학습 방법에 충분히 대항할 수 있습니다.