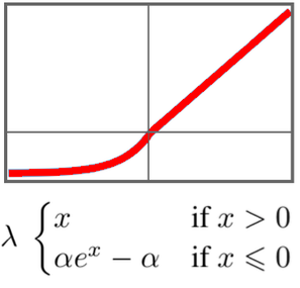
음성 분류자 훈련하기
이 예는 간단한 신경망을 음성 분류를 위해 어떻게 훈련하는지 또 이를 통해 음성 특징을 어떻게 추출 하는지를 보여줍니다.
다양한 이야기들에 의한 0에서 9까지의 숫자 발음 녹음 및 그 라벨, 말하는 사람의 ID로 이루어진 "Spoken Digit Commands" 데이터 집합을 ResourceData에서 가져옵니다.
음성 데이터의 초기 부호화는 이미지 데이터의 그것보다 더 복잡하고 더 중요합니다. 음성에는 벡터열에 기초한 신호의 압축 표현을 만드는 "AudioMFCC" 등 다양한 부호화 알고리즘을 사용할 수 있습니다.
GatedRecurrentLayer 스택을 기반으로하여 분류 네트워크를 정의합니다. NetBidirectionalOperator를 사용하여 층을 양방향으로 만들어 시퀀스를 양방향으로 읽고 결과를 종합할 수 있습니다. 순환의 최종 상태는 SequenceLastLayer에서 추출할 수 있습니다.
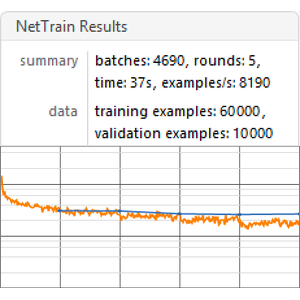
NetTrain을 사용하여 네트워크를 훈련합니다. 데이터의 5%는 검증을 위해 남겨 둡니다.
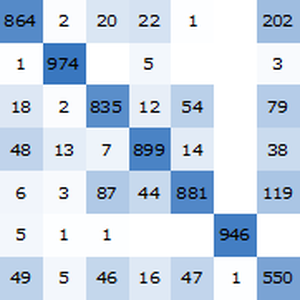
마지막 네트워크를 검증 집합의 예로 평가합니다.
NetMeasurements를 사용하여 검증 집합에 대한 정확도를 계산합니다.
이 네트워크는 마지막 분류층을 제거하면 높은 수준의 특징 추출기로 사용할 수 있습니다.
추출기를 사용하여 새로운 모델을 작은 데이터에서 매우 신속하게 훈련할 수 있습니다. 예를 들어, 단 50 개의 훈련 예만 사용하고 Classify에서 새로운 분류자를 훈련합니다.
이 분류자의 성능 정보를 확인합니다.