Entraînez un classifieur audio
Cet exemple illustre comment entraîner un réseau neuronal simple à la classification audio et comment l'utiliser pour extraire des caractéristiques audio.
Récupérez le jeu de données "Spoken Digit Commands" à partir de ResourceData, composé d'enregistrements de différents locuteurs prononçant des chiffres de 0 à 9 avec leur étiquette et un identifiant de locuteur.
L'encodage initial des données audio est plus complexe et plus crucial que pour les données image. Différents algorithmes d'encodage sont disponibles pour l'audio, notamment l'"AudioMFCC" qui produit une représentation compacte du signal en fonction d'une séquence de vecteurs.
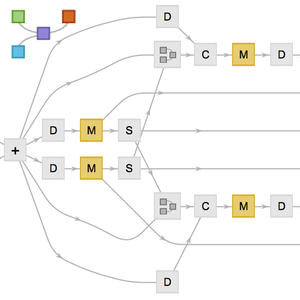
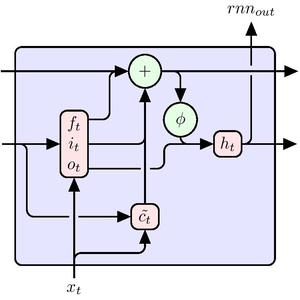
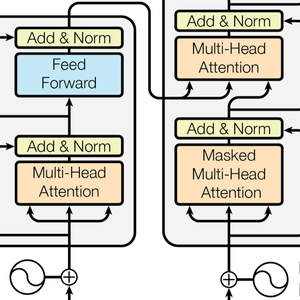
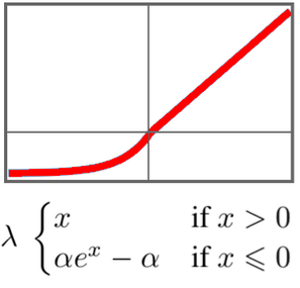
Définissez un réseau de classification basé sur un ensemble de couches GatedRecurrentLayers. NetBidirectionalOperator peut être utilisé pour rendre les couches bidirectionnelles, lire la séquence dans les deux sens et concaténer les résultats. L'état final de la récurrence est extrait par SequenceLastLayer.
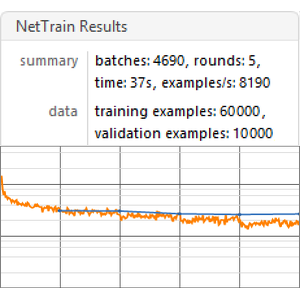
Entraînez le réseau à l'aide de NetTrain et conservez 5 % des données pour la validation.
Évaluez le réseau final à l'aide d'un exemple tiré de l'ensemble de tests.
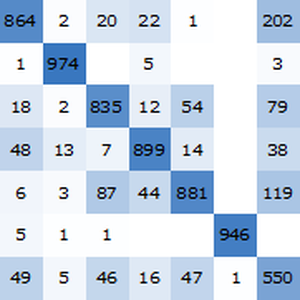
Calculez la précision sur l'ensemble de tests en utilisant NetMeasurements.
Le réseau peut être utilisé comme un extracteur d'éléments de haut niveau en supprimant les dernières couches de classification.
L'extracteur peut être utilisé pour entraîner un nouveau modèle très rapidement et avec une petite quantité de données. À titre d'exemple, entraînez un nouveau classifieur avec Classify en utilisant seulement 50 exemples d'entraînement.
Récupérez les informations sur les performances du classifieur.