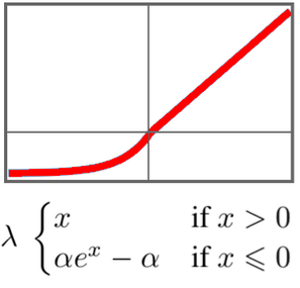
Entraînez un réseau pour modéliser la langue anglaise
Cet exemple illustre comment entraîner un réseau neuronal récurrent pour générer du texte en anglais.
Tout d'abord, créez 300 000 exemples d'entraînement de 25 caractères chacun à partir de deux romans.
Échantillonnez les données qui se présentent sous la forme d'un problème de classification. Avec une séquence de caractères spécifique, prédisez le caractère suivant.
Récupérez la liste de tous les caractères du texte.
Créez un réseau qui prédit une séquence entière en une seule fois. Remarquez qu'au lieu d'utiliser une couche SequenceLastLayer avant une couche LinearLayer, on utilise NetMapOperator. Par conséquent, le réseau prédit simultanément le caractère suivant dans la séquence pour chaque caractère, plutôt que de simplement prédire le dernier caractère de la séquence.
Créez maintenant un réseau "Teacher Forcing" qui prend une phrase cible et la présente "en décalage" au réseau : pour une phrase de longueur 26, présentez les caractères 1 à 25 afin de produire des prédictions pour les caractères 2 à 26, comparé aux caractères réels sur CrossEntropyLossLayer pour produire une perte.
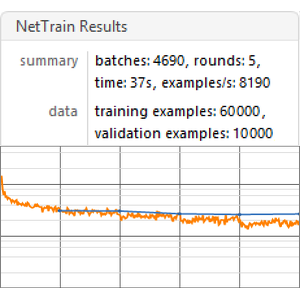
Entraînez le réseau sur les séquences d'entrée à partir des données originales.
Extrayez la chaîne de prédiction des résultats.
Créez une chaîne de prédiction d'un seul caractère à partir de celle-ci.
Testez le prédicteur.
Créez un objet NetStateObject pour générer du texte efficacement.
Générez 200 caractères selon la distribution apprise par le réseau. Le texte généré présente des similitudes avec l'anglais, mais beaucoup de mots ne sont même pas anglais, car il a été entraîné sur un petit corpus (environ deux millions de caractères).
Comparez avec un réseau similaire entraîné sur environ un milliard de caractères.