Utilisez les réseaux neuronaux de transformateurs
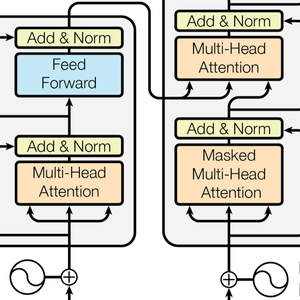
Les réseaux neuronaux de transformateurs sont une classe récente de réseaux neuronaux pour des séquences, basées sur l'auto-attention, qui se sont avérées bien adaptées au texte et qui font actuellement progresser le traitement du langage naturel de façon importante. Voici l'architecture illustrée dans l'article phare Attention Is All You Need.
Cet exemple illustre les réseaux neuronaux des transformateurs (GPT et BERT) et explique comment ils peuvent être utilisés pour créer un modèle personnalisé d'analyse de sentiment.
Téléchargez les modèles GPT et BERT à partir de Neural Net Repository.
Ces modèles sont entraînés sur de grands corpus de textes (généralement des milliards de mots) sur des tâches d'apprentissage non supervisées, comme la modélisation linguistique. Par conséquent, ils fournissent d'excellents extracteurs de caractéristiques qui peuvent être utilisés pour diverses tâches. À partir d'une phrase, ces modèles produisent une liste de vecteurs numériques, un pour chaque mot ou sous-mot. Ces vecteurs sont une représentation numérique de la "signification" de chaque mot ou sous-mot.
Explorez maintenant l'intérieur du réseau BERT. Vous pouvez le faire en cliquant sur la partie du réseau qui vous intéresse (et en cliquant à nouveau pour aller plus loin) ou en utilisant NetExtract.
La chaîne d'entrée est d'abord tokenisée en mots ou sous-mots. Chaque token est ensuite intégré dans des vecteurs numériques de taille 768.
L'architecture du transformateur traite ensuite les vecteurs en utilisant 12 blocs structurellement autonomes et identiques, empilés dans une chaîne. La partie clé de ces blocs est le module d'attention, constitué de 12 transformations parallèles de l'auto-attention, alias "têtes d'attention".
Extrayez une de ces têtes d'attention. Chaque tête utilise une couche AttentionLayer dans son noyau central. En résumé, chaque vecteur 768 calcule sa valeur suivante (un vecteur 768 à nouveau) en déterminant les vecteurs qui lui sont pertinents. Remarquez ici l'utilisation de NetMapOperator.
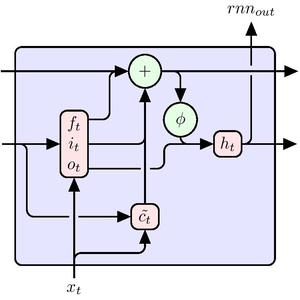
AttentionLayer peut exploiter les dépendances à long terme au sein des séquences d'une manière beaucoup plus directe que les couches récurrentes telles que LongShortTermMemoryLayer et GatedRecurrentLayer. Le schéma suivant illustre la connectivité de différentes architectures de séquences.
GTP a une architecture similaire à celle de BERT. Sa principale différence réside dans le fait qu'il utilise une architecture d'auto-attention causale, au lieu d'une architecture d'auto-attention simple. Ceci peut être vu par l'utilisation du masque "Causal" dans la couche AttentionLayer.
L'attention causale est moins efficace dans le traitement de texte car un token particulier ne peut pas obtenir d'informations sur de futurs tokens. D'autre part, une attention causale est nécessaire pour la génération de texte : GPT est capable de générer des phrases, alors que BERT ne peut que les traiter.
De nombreux articles sur la recherche rapportent que les transformateurs surpassent les réseaux récurrents pour de nombreuses tâches linguistiques. C'est ce qui ressort d'une analyse classique des sentiments d'un film.
Ici, GPT et BERT sont comparés avec les intégrations de mots de base GloVe et ELMo. Ce sont les derniers développements en matière de réseaux récurrents en NLP.
Certains des réseaux ont besoin d'un peu plus d'opérations pour qu'ils prennent une chaîne comme entrée et une séquence de vecteurs en sortie.
Essayons plusieurs stratégies de mise en commun pour créer un classifieur de phrases à partir des séquences d'intégration de mots.
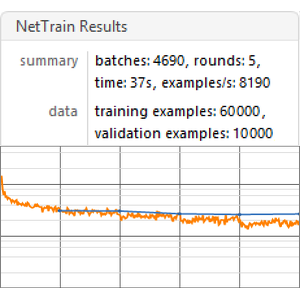
Créez une fonction de test de performance (benchmarking) qui entraîne et mesure la performance d'un modèle sur la base d'une intégration donnée.
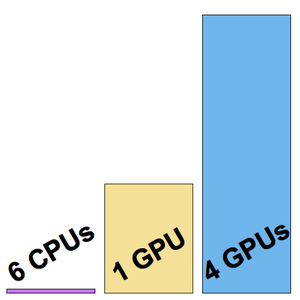
Exécutez le test de performance (un processeur graphique GPU est conseillé) sur toutes les intégrations.
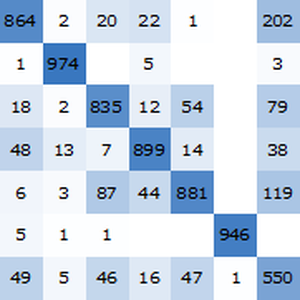
Visualisez le rapport du test de performance. Comme prévu, les insertions contextuelles de mots, basées sur les derniers transformateurs, surpassent les insertions ELMo, basées sur des réseaux récurrents, qui surpassent largement les insertions GloVe (indépendantes du contexte) classiques. Remarquez que BERT est meilleur que GPT (15 % contre 18 % d'erreurs), puisque GPT est pénalisé par sa contrainte de causalité.