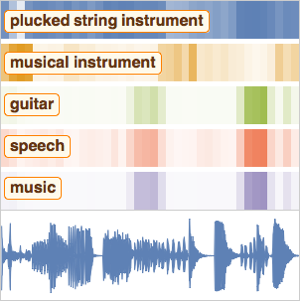
ニューラルネットを使って音声(スピーチ)を調べる
この例では,組込みのSpeechRecognize関数を使って音声を認識する.信号から文字リストへの音声転写にはWolfram Neural Net Repositoryからのニューラルネットも使われる.
合成された音声信号から始める.
音声オブジェクトに含まれる音声を認識する.
次に,訓練済みの音声認識ネットを入手する.
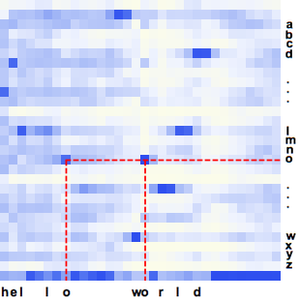
ニューラルネットを次の合成音声で評価する.このネットワークは音声録音から認識された文字のリストを返す.
文字を繋げて認識した音声の最初のバージョンを得る.
このネットワークは,一字が複数のフレームにまたがることも考慮して,CTC損失を使って入力からのフレームのリストを文字のリストにマッピングするように訓練されている.
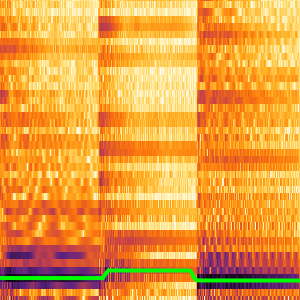
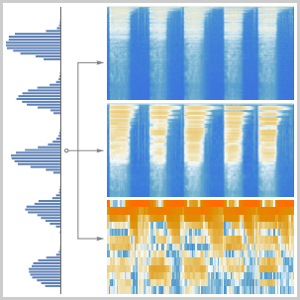
CTCの復号化の直前にこのネットワークの出力を可視化して任意の時点におけるすべての文字の確率を得ることができる.下の軸は,各フレームに確率が最大の文字を割り当てた中間段階の復号化でラベルが付けられている.