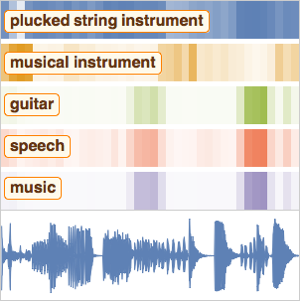
音事象の検出ネットを訓練する
場合によっては,録音の音事象の場所を見付けるためにネットワークを訓練したいのに,特定の事象が録音に存在しているかどうかだけを記述してその事象がどこにあるかは記述していない「弱ラベル」が付いたデータにしかアクセスできないこともあるだろう.データの制限はあっても,弱ラベルデータの訓練を通して音事象の局所化でよい結果を得ることは可能である.
Wolfram Data RepositoryからAudio Cats and Dogsデータ集合を取り出す.
このデータ集合は猫と犬の注釈付き録音からなっている.
録音時間は1秒から18秒までとさまざまである.
データ集合を操作してニューラルネットの訓練がしやすい形式にし,訓練用と検証用の部分集合に分割する.
訓練データの合計時間を調べる.
検証データを合計する.
音声信号のネットワークへのフィードには"AudioMelSpectrogram"エンコーダが使われている.データ量が比較的小さいので,データの増強を行って訓練をより効果的にすることができる.
ネットそれ自体は,回帰層のスタック(GatedRecurrentLayer)と,結果を時間次元にプールするAggregationLayerに基づいている.これで,ネットがシーケンスの代りに単一の分類結果を出力することが可能になる.
訓練を始める.
訓練済みのネットを抽出し,エンコーダを拡張されていないもので置換する.
検証集合におけるパフォーマンスのレポートを作成する.
AggregationLayerを取り除いて切り取られたネットにSoftmaxLayerを再び加えると,単一の分類の結果の代りにクラス確率のシーケンスを返すネットワークが得られる.
ネットワークの出力を取ってTimeSeriesの連想を可能なラベルの確率とともに返す関数を定義する.
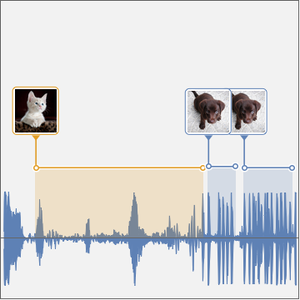
これで,時間分解ネットが検証できる.検証用データ集合からの犬と猫のサンプルを繋いで信号を構築する.
このネットで計算した確率の時系列をプロットする.
ネットの結果を検証信号の上にプロットする.
クラス確率が閾値より高くなる時間間隔を計算する関数と,これらの間隔に対応する長方形を計算する関数を定義する.
間隔を計算する.
間隔を録音の波形の上にプロットする.