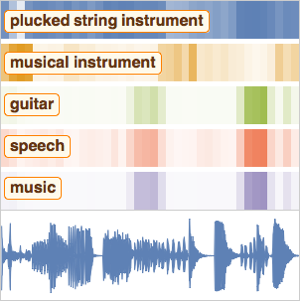
音声に含まれるキーワードを認識する
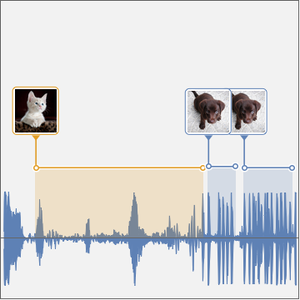
単純な音声転写に加え,録音が特定の単語集合のどれかを含んでいる確率を計算することで,ネットワークによって導入されるかもしれないスペルミスに対するある程度の耐性が提供される.さらに,録音のどこで特定の言葉が発せられたかが分かると大変役に立つ.
Wolfram Neural Net Repositoryからの訓練済みの音声認識ネットワークを使って,特定の単語が録音に含まれている確率を計算する.このネットワークについての詳細はここをご覧いただきたい,
Wolfram Data Repositoryの訓練データ"Spoken Digit Commands"からサンプルをダウンロードして見ることから始める.
このネットを使って常に任意の単一の文字の確率を計算する.
CTCLossLayerを使ってネットの出力によって与えられた特定の文字列の負の対数尤度が計算できる.
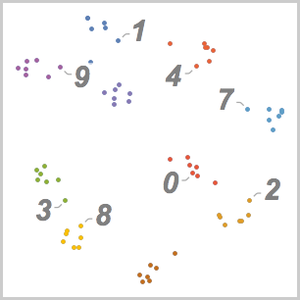
転写されたものが0から9までの数字の1つである対数尤度を計算する.
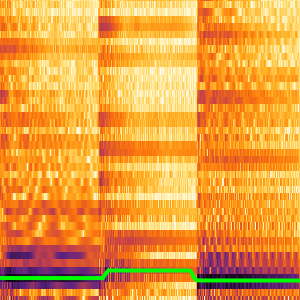
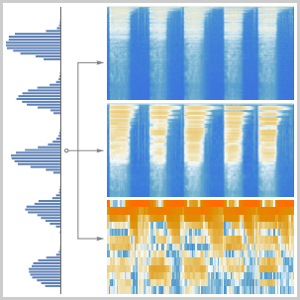
スライディングウィンドウを使って,より長い音声サンプルについて同様の操作を行うことができる.
このネットを使って常に任意の単一の文字の確率を計算する.
転写候補を選ぶ.
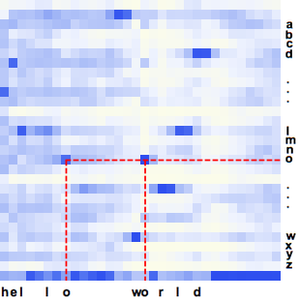
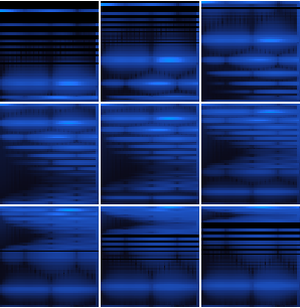
ネットが計算した確率を分割して信号の部分集合を調べることができる.CTC損失は各部分のすべての選択肢について計算することができる. これを使って特定の選択肢が特定の部分の転写となる対数尤度が計算できる.BlockMapを使って音声信号の分割部分に関数を適用する.
これで3つの単語の確率を時間の関数としてプロットできる.