음성의 넷 인코더
음성 특유의 다양한 NetEncoder 객체가 Audio 객체와 신경망 프레임워크를 확실히 통합하는 데 사용할 수 있게 되었습니다. 인코더는 데이터를 신경망에 주입하는 간단한 방법을 제공하므로, 이 프레임워크의 중심에 위치합니다.
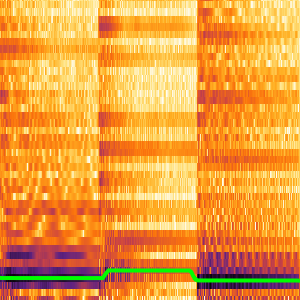
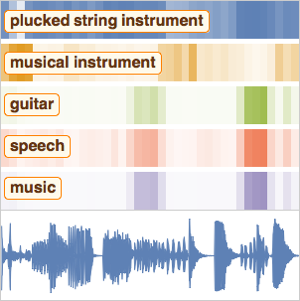
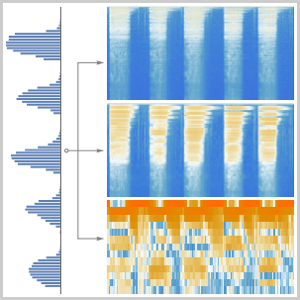
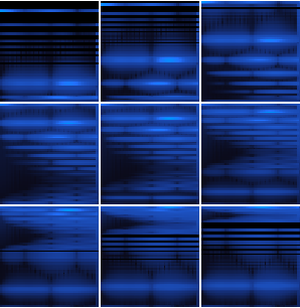
새소리 녹음에서 계산된 각 인코더의 특징을 조사합니다.
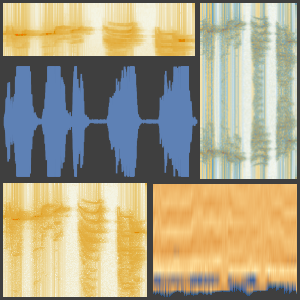
"Audio" 넷 인코더는 리샘플링 및 다운믹싱 단계 후에 파형을 돌려주기만 합니다.
전체 Wolfram 언어 입력 표시하기
"AudioSTFT" 넷 인코더는 입력 신호의 분할 부분인 푸리에 변환을 계산합니다. 이 특징은 시간과 주파수의 정보가 모두 포함되어 있습니다.
전체 Wolfram 언어 입력 표시하기
"AudioSpectrogram" 넷 인코더는 입력 신호의 분할 부분에 대해 계산된 파워 스펙트럼을 반환합니다.
전체 Wolfram 언어 입력 표시하기
"AudioMelSpectrogram" 넷 인코더는 인간의 피치 인식을 모방하기 위해 주파수의 빈이 비선형 간격이되는 필터를 씌운 스펙트로그램을 반환합니다.
전체 Wolfram 언어 입력 표시하기
"AudioMFCC" 넷 인코더는 신호에 포함된 대부분의 정보를 유지하면서 멜 스펙트로그램에 대해 한층 더 차원을 감소합니다.
전체 Wolfram 언어 입력 표시하기