Tippfehler ohne Wörterbuch korrigieren
In diesem Beispiel werden die Sequenz getippter Zeichen als beobachtete und die Sequenz korrekter Zeichen als verborgene Zustände modelliert. Dazu werden zwei unterschiedliche Modelle zur Bestimmung korrekter Buchstaben und zur Tippfehlerkorrektur angewendet. Das erste Modell wendet einen Markov-Prozess erster Ordnung an, um die Häufigkeit zu ermitteln, mit der ein Buchstabe auf einen bestimmten Buchstaben folgt. Das zweite Modell wendet Markov-Zustände zweiter Ordnung an, um die Häufigkeit zu ermitteln, mit der ein Buchstabe auf die beiden letzten gegebenen Buchstaben folgt.
Nehmen Sie Darwins The Origin of Species und konvertieren Sie alle Symbole, die keine Buchstaben sind, in Leerzeichen.
| In[1]:= |  X |
| In[2]:= | X |
Bauen Sie Tippfehler mit einer Rate von 20 % ein, indem Sie beliebig einen Buchstaben durch einen seiner unmittelbaren Nachbarn auf der englischen Standard-Tastatur ersetzen. Das Leerzeichen wird jedoch immer korrekt angegeben.

| In[4]:= |  X |
| In[5]:= |  X |

| Out[6]= | 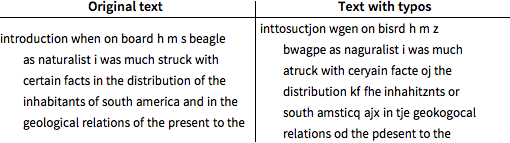 |
Verwenden Sie die ersten 80 000 Zeichen als Testsequenz und den verbleibenden Text als Trainingssequenz. Die Testsequenz weist 16,5 % Tippfehler auf, also weniger als 20 %, da das Leerzeichen nie falsch abgetippt wurde.
| In[7]:= |  X |
| Out[7]= |
Modellieren Sie den Strom der getippten Zeichen anhand eines verborgenen Markov-Prozesses. Richtige Zeichen sind verborgene, die falsch getippten Zeichen beobachtete Zustände.
| In[8]:= |  X |
Schätzen Sie den verborgenen Markov-Prozess anhand der Trainingsdaten.
| In[9]:= |  X |
| Out[9]= |
| In[10]:= |  X |
Verwenden Sie die Posterior-Methode, um Tippfehler im Testteil des fehlerübersäten Texts zu korrigieren.
| In[11]:= |  X |
| Out[11]= |
Die Fehlerquote im korrigierten Text beträgt immer noch 11 %, also 5,5 % weniger als der ursprüngliche abgetippte Text.

| Out[12]= | 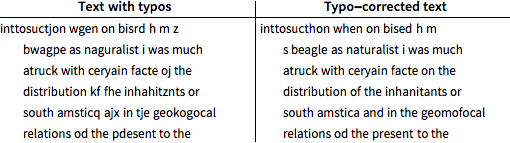 |
| In[13]:= |  X |
| Out[13]= |
Modellieren Sie die Evolution der verborgenen Zustände anhand eines Markov-Prozesses zweiter Ordnung, d.h. mit der Annahme, dass die Wahrscheinlichkeit des Zeichens von den zwei vorangehenden Zeichen abhängt. Der Markov-Prozess zweiter Ordnung wird als Markov-Prozess erster Ordnung mit einem erweitertem Zustandsraum von Paaren aufeinanderfolgender Zeichen modelliert.
| In[14]:= |  X |
| In[15]:= | 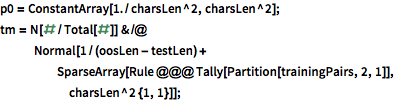 X |
Die Auftrittswahrscheinlichkeit des getippten Zeichens ist nur abhängig vom zugrundeliegenden richtigen Zeichen.
| In[16]:= | X |
Wiederholen Sie die Posterior-Methode mit dem HMM höherer Ordnung.
| In[17]:= |  X |
| Out[17]= |
Die Fehlerquote liegt nun bei unter 6 %.
| In[18]:= |  X |
| Out[18]= |

| Out[19]= | 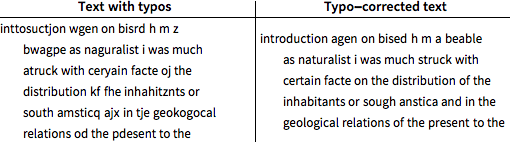 |