전이 학습을 통한 음성 데이터 집합 분류하기
때로 네트워크의 훈련에 사용할 수 있는 데이터의 양이 현재 진행하는 작업에 충분하지 않은 경우가 있습니다. 전이 학습은 이러한 문제에 대한 해결책이 될 수 있습니다. 네트워크를 처음부터 훈련하는 대신에 원래의 작업과는 다르지만 유사한 관련 작업을 위해 이미 훈련된 넷을 출발점으로 사용함으로써 전이 학습을 실행할 수 있습니다.
ESC-50 dataset를 다운로드 합니다.
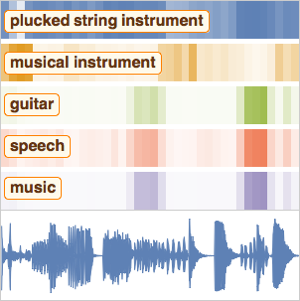
메타 데이터를 가져옵니다. 이 데이터 집합은 2000개의 환경 음성 녹음의 라벨 집합입니다. 각 파일은 5초짜리 녹음으로, 50 종류의 의미 클래스로 정리하고 있습니다.
메타 데이터에서 샘플을 조사합니다.
데이터를 훈련과 검증의 부분 집합으로 나눕니다.
사용할 수 있는 클래스를 찾아봅니다.
AudioIdentify 네트워크의 분류자 층을 삭제하고 특징 추출 네트워크를 구축합니다.
특징 추출기에 추가할 간단한 선형 분류자 네트워크를 구축합니다.
넷 전체를 다시 훈련시키고, NetTrain의 LearningRateMultipliers 옵션을 지정하여 분류 층만을 훈련하는 대신에, 특징 추출기 층의 결과를 미리 계산하여 분류자를 훈련시킬 수 있습니다. 이렇게하면, 불필요한 네트워크 전체의 평가를 피할 수 있습니다.
NetTrain을 사용하여 분류자 네트워크를 훈련합니다.
NetJoin을 사용하여 특징 검출기의 네트워크와 훈련된 분류자를 결합합니다.
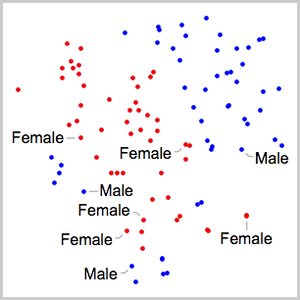
ClassifierMeasurements를 사용하여 검증 데이터의 정답율을 계산하고 네 개의 최저 클래스의 혼동 행렬을 플롯합니다.