기저 추적
기저 함수 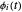 의 집합이 주어 졌을 때, 신호
의 집합이 주어 졌을 때, 신호 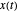 는 선형 결합
는 선형 결합 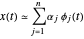 에 의해 근사할 수 있습니다. 일반적으로 기저가 클수록 신호의 근사는 향상됩니다. 그러나 합리적인 근사를 위해 모든 신호가 모든 기저 함수를 필요로 하는 것은 아닙니다. 기저 추적은 과잉 결정될 가능성이 있는 기저 함수의 큰 집합 (혹은 사전)의 작은 부분 집합을 선택하는 것입니다.
에 의해 근사할 수 있습니다. 일반적으로 기저가 클수록 신호의 근사는 향상됩니다. 그러나 합리적인 근사를 위해 모든 신호가 모든 기저 함수를 필요로 하는 것은 아닙니다. 기저 추적은 과잉 결정될 가능성이 있는 기저 함수의 큰 집합 (혹은 사전)의 작은 부분 집합을 선택하는 것입니다.
이 예는 Fit의 FitRegularization 옵션을 사용하여 쉽고 효율적으로 기저를 추적하는 방법을 보여줍니다.
이산 시간 샘플링을 사용하는 신호의 경우 재구성은 행렬 방정식 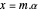 로 주어질 수 있습니다. 여기서
로 주어질 수 있습니다. 여기서 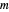 은 요소
은 요소 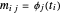 를 가지는 행렬입니다. 과잉 결정 시스템의 기저 함수의 경우 최고의 근사를 제공하는 계수 α는 최소 제곱으로 쉽게 찾을 수 있습니다.
를 가지는 행렬입니다. 과잉 결정 시스템의 기저 함수의 경우 최고의 근사를 제공하는 계수 α는 최소 제곱으로 쉽게 찾을 수 있습니다. 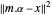 을 최소화하는 대신
을 최소화하는 대신 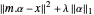 을 주기 위하여 L1 정규화 항이 추가되면 매개 변수
을 주기 위하여 L1 정규화 항이 추가되면 매개 변수 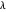 에 대해 충분히 큰 값은 α의 구성 요소가 0이 되도록합니다. Fit에서 새로운 옵션 FitRegularization을 사용하면 문제를 효율적으로 해결할 수 있습니다.
에 대해 충분히 큰 값은 α의 구성 요소가 0이 되도록합니다. Fit에서 새로운 옵션 FitRegularization을 사용하면 문제를 효율적으로 해결할 수 있습니다.
기저 함수의 큰 사전의 예로 가보르 함수 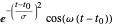 및
및 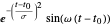 의 기저를 사용합니다.
의 기저를 사용합니다.
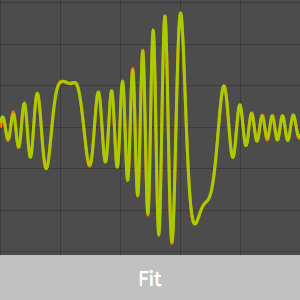
다음은 가보르 함수의 샘플을 나타내는 플롯입니다.
시간 샘플 간격이 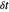 인 0부터 1의 간격에서
인 0부터 1의 간격에서 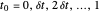 ,
, 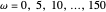 및 고정된
및 고정된 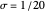 의 기저 함수 집합은 다양한 신호를 엄격하게 표현할 수 있습니다.
의 기저 함수 집합은 다양한 신호를 엄격하게 표현할 수 있습니다.
기저 행렬은 DesignMatrix를 사용하여 구축할 수 있습니다.
이 행렬은 매우 크지만, 표현 정확도의 손실이 적기 때문에 가보로 함수가 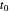 부터 급속히 감쇠한다는 사실을 통해 임계값을 사용하여 드문드문하게 만들 수 있는 특성을 사용할 수 있습니다.
부터 급속히 감쇠한다는 사실을 통해 임계값을 사용하여 드문드문하게 만들 수 있는 특성을 사용할 수 있습니다.
이제 신호를 고려해봅니다.
이 신호는 항상 샘플을 평가하여 이산화할 수 있습니다.
최소 제곱 적합를 통해 이 함수가 기저 함수로 얼마나 잘 표현되어 있는지 알 수 있습니다. 행렬이 매우 크기 때문에, 다소 시간이 걸립니다.
전체 표현 오차는 사실상 기계 정밀도의 반올림입니다.
L1 정규화를 사용하여 듬성듬성한 적합을 구합니다. 이 방법은 드문드문한 알고리즘을 사용하기 때문에 최소 제곱 적합보다 빨리 계산할 수 있습니다.
희소 표현은 30561개의 기저 성분 중 50개만 사용됩니다. 이는 실제로 함수 형식을 얻기에 충분히 작습니다.
오차를 나타냅니다.
이러한 기저 성분들만으로 최소 제곱 적합을 실시하면, 적합을 약간 개선할 수 있습니다.
매개 변수 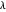 를 변경하여 오차를 조정할 수 있습니다. 일반적으로
를 변경하여 오차를 조정할 수 있습니다. 일반적으로 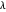 가 크면 기저 함수의 수는 적고 오차가 많아집니다. 한편,
가 크면 기저 함수의 수는 적고 오차가 많아집니다. 한편, 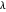 가 작으면 기저 함수의 수는 많고 오차는 작아집니다.
가 작으면 기저 함수의 수는 많고 오차는 작아집니다. 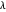 를 변경했을 때의 오차를 플롯합니다.
를 변경했을 때의 오차를 플롯합니다.