
| 22 | Aprendizaje automático |
Hasta este punto en el libro, cuando se ha querido indicar a Wolfram Language que se desea hacer alguna cosa, hay que escribir código para decirle exactamente lo que tiene que hacer. Sin embargo, Wolfram Language tiene la capacidad de aprender lo que tiene que hacer refiriéndose a ejemplos, utilizando la idea del aprendizaje de máquinas.
Aquí se explicará cómo puede entrenarse al lenguaje para hacer eso. Pero se verán primero algunas funciones nativas que ya han sido entrenadas con un gran número de ejemplos.
| In[1]:= |
| Out[1]= |
Wolfram Language puede también realizar tareas considerablemente más difíciles, de “inteligencia artificial”, tales como la identificación de imágenes.
| In[2]:= | 
|
| Out[2]= |
Existe una función general, Classify, a la que se le han enseñado varios tipos de clasificación. Por ejemplo, clasificar el “sentimiento” de un texto.
| In[3]:= |
| Out[3]= |
Un texto pesimista se clasifica como de sentimiento negativo:
| In[4]:= |
| Out[4]= |
Uno mismo puede llevar a cabo el entrenamiento de Classify. Un ejemplo sencillo es la clasificación de dígitos manuscritos como 0 o 1. Se le da a Classify una colección de ejemplos de entrenamiento, seguidos por un dígito particular escrito a mano. La respuesta será 0 o 1 para ese dígito manuscrito.
Con ejemplos de entrenamiento, Classify identifica correctamente un 0 escrito a mano:
| In[5]:= | 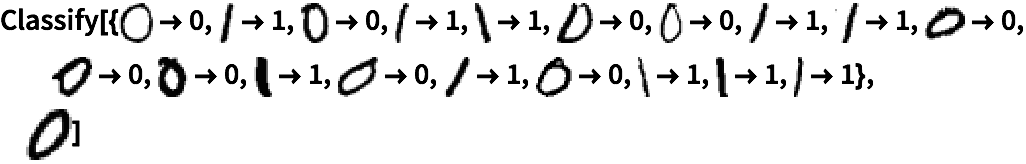
|
| Out[5]= |
Para darse una idea de cómo trabaja lo anterior, y porque es útil por sí mismo, se describirá la función Nearest, que encuentra cuál de los elementos de una lista es el más próximo al que uno le dé.
Encuentre cuál de los elementos de la lista es el más próximo a 22:
| In[6]:= |
| Out[6]= |
Encuentre los tres números más próximos:
| In[7]:= |
| Out[7]= |
En la lista que sigue, encontrar los 3 colores que estén más próximos al que se da:
| In[8]:= |
| Out[8]= |
| In[9]:= |
| Out[9]= |
También existe la noción de cercanía para imágenes. Y, aunque dista de ser todo lo que hay, esto es, en efecto, parte de lo que usa ImageIdentify.
Otro asunto que también está relacionado es el reconocimiento de texto (reconocimiento óptico de caracteres u OCR). Se toma una porción de texto para hacerla borrosa.
| In[10]:= |
| Out[10]= |
TextRecognize tiene la capacidad de reconocer el texto original a partir de uno borroso.
Reconozca el texto en la imagen:
| In[11]:= |
| Out[11]= |
Si el texto está demasiado borroso,TextRecognize no podrá reconocer lo que dice, aunque probablemente una persona tampoco.
Genere una secuencia de porciones de texto progresivamente más borrosas:
| In[12]:= |
| Out[12]= |
A medida que el texto se hace más borroso, TextRecognize comete errores, hasta que desiste por completo:
| In[13]:= |
| Out[13]= |
Algo similar sucede si se hace más y más borrosa la imagen de un guepardo. Mientras la imagen esté más o menos nítida, ImageIdentify la identificará correctamente como guepardo. Pero cuando es ya demasiado borrosa, ImageIdentify comienza por confundirla con un león, hasta que su mejor conjetura es que se trata de una persona.
Haga cada vez más borrosa la imagen de un guepardo:
| In[14]:= | 
|
| Out[14]= | 
|
Cuando la imagen está ya demasiado borrosa, ImageIdentify deja de suponer que es un guepardo:
| In[15]:= | 
|
| Out[15]= | 
|
ImageIdentify normalmente contesta lo que supone es la identificación más verosímil. Sin embargo, se le puede dar una lista de identificaciones posibles, comenzando por la más verosímil. Aquí aparecen las 10 identificaciones posibles más verosímiles, en todas las categorías, comenzando por la primera.
ImageIdentify supone que esto podría ser un guepardo, pero es más verosímil que sea un león o hasta un perro:
| In[16]:= | 
|
| Out[16]= | 
|
Cuando la imagen está suficientemente borrosa, ImageIdentify puede hacer suposiciones a lo loco sobre lo que puede ser:
| In[17]:= | 
|
| Out[17]= | 
|
En el aprendizaje de máquinas se suele dar el entrenamiento explícitamente, por ejemplo, diciendo “esto es un guepardo”, “esto es un león”. Aunque a veces simplemente se desea encontrar categorías de cosas sin un entrenamiento específico previo.
Una forma de lograr lo anterior es comenzar por tomar una colección de cosas, como colores, y entonces formar cúmulos con las que sean similares. Esto puede lograrse usando FindClusters.
Forme “cúmulos” de colores similares en listas separadas:
| In[18]:= |
| Out[18]= |
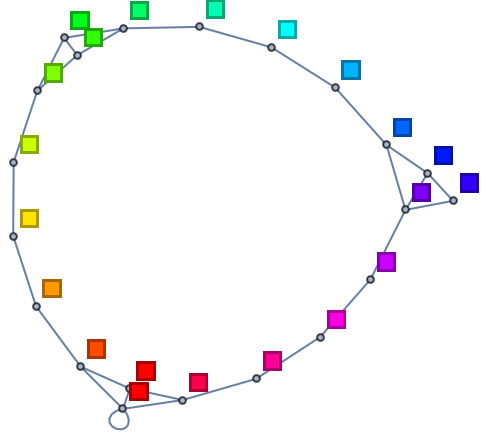
También puede obtenerse una visión diferente conectando cada color con los tres más similares en la lista y, entonces, hacer un grafo con las conexiones. En el ejemplo anterior se obtienen así tres subgrafos no conectados.
| In[19]:= |
| Out[19]= | 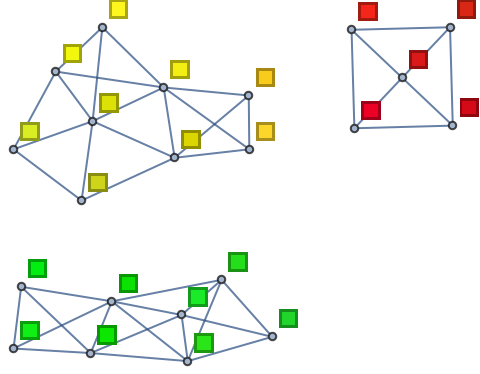
|
Un dendrograma es una representación gráfica tipo árbol, que permite observar una jerarquía completa de qué está cerca de qué.
Muestre los colores cercanos agrupados sucesivamente:
| In[20]:= |
| Out[20]= | 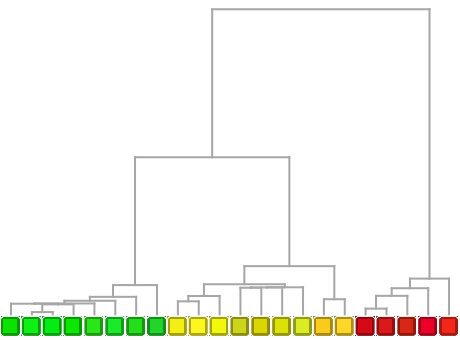
|
Al comparar cosas, ya sean colores o fotos de animales, puede pensarse en identificar aquellas características que permitan distinguir unas de otras. En el caso de colores, una característica podría ser qué el grado de claridad del color, o el grado de rojo que contiene. Si se trata de fotos de animales, una característica podría ser qué tan peludo se ve el animal, o cuán puntiagudas tiene sus orejas.
En Wolfram Language, FeatureSpacePlot toma colecciones de objetos y trata de encontrar cuáles serían sus “mejores” características distintivas y, entonces, usar sus valores para posicionar los objetos dentro de una gráfica.
FeatureSpacePlot no informa explícitamente sobre cuáles son las características que usa. De hecho, por lo general, son bastante difíciles de describir. Pero, a fin de cuentas, lo que sucede es que FeatureSpacePlot acomoda las cosas de modo tal que los objetos que tienen características similares quedan cerca unos de otros.
FeatureSpacePlot acomoda los colores similares en posiciones cercanas:
| In[21]:= |
| Out[21]= | 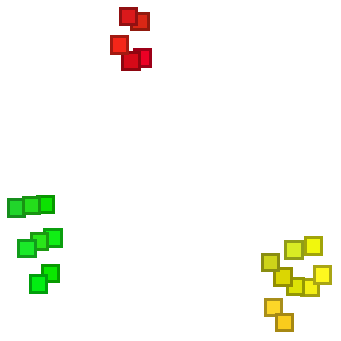
|
Por ejemplo, si se usan100 colores tomados completamente al azar, entonces FeatureSpacePlot colocará juntos aquellos que considere similares.
100 colores aleatorios acomodados mediante FeatureSpacePlot:
| In[22]:= |
| Out[22]= | 
|
Ahora se hará el mismo tipo de tratamiento con imágenes de letras.
Forme la imagen rasterizada de cada una de las letras del alfabeto (en inglés):
| In[23]:= |
| Out[23]= |
FeatureSpacePlot utilizará las características visuales de estas imágenes para disponerlas gráficamente. El resultado es que aquellas letras con imágenes similares, como y, v, o e, c, terminarán quedando próximas entre ellas.
| In[24]:= |
| Out[24]= | 
|
Aquí se hace lo mismo, pero esta vez con fotos de gatos, coches y sillas. FeatureSpacePlot separa inmediatamente los diferentes tipos de cosas.
FeatureSpacePlot coloca claramente separadas las fotos de cosas de diferentes clases:
| In[25]:= | 
|
| Out[25]= | 
|
| LanguageIdentify[texto] | identifica en qué lengua humana está el texto | |
| ImageIdentify[imagen] | identifica de qué es la imagen | |
| TextRecognize[texto] | reconoce el texto a partir de una imagen (OCR) | |
| Classify[entrenamiento,datos] | clasifica datos a partir de entrenamiento con ejemplos | |
| Nearest[lista,ítem] | encuentra cuál elemento de lista es el más próximo a ítem | |
| FindClusters[lista] | encuentra cúmulos de elementos similares | |
| NearestNeighborGraph[lista,n] | conecta elementos de lista con sus n vecinos más cercanos | |
| Dendrogram[lista] | hace un árbol jerárquico de relaciones entre elementos | |
| FeatureSpacePlot[lista] | grafica los elementos de lista en un “espacio de características” |


22.3Forme una tabla de identificaciones de la imagen de un tigre, con borrosidades del 1 al 5. »



22.10Haga un grafo de los 2 colores que sean vecinos más cercanos a cada uno de los colores en Table[Hue[h], {h, 0, 1, .05}]. »
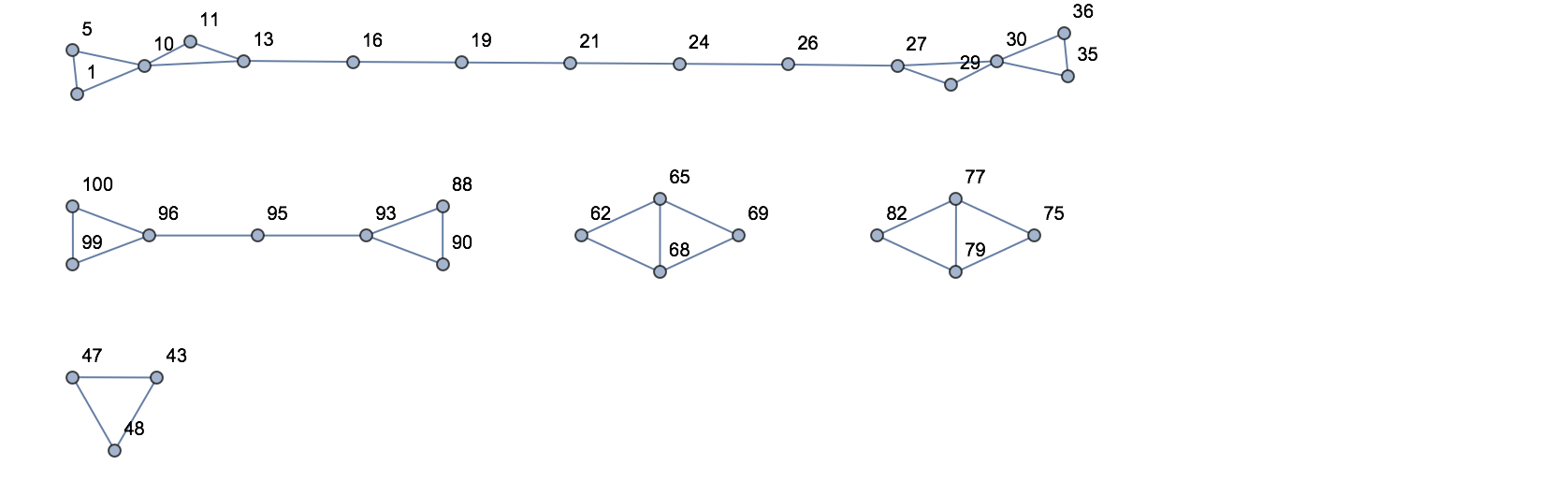
22.11Genere una lista de 100 números aleatorios entre 0 y 100, y hacer un grafo de los dos vecinos más próximos para cada uno. »

22.13Produzca imágenes rasterizadas de las letras del alfabeto inglés en tamaño 20, y luego haga un grafo de los 2 vecinos más próximos para cada uno. »
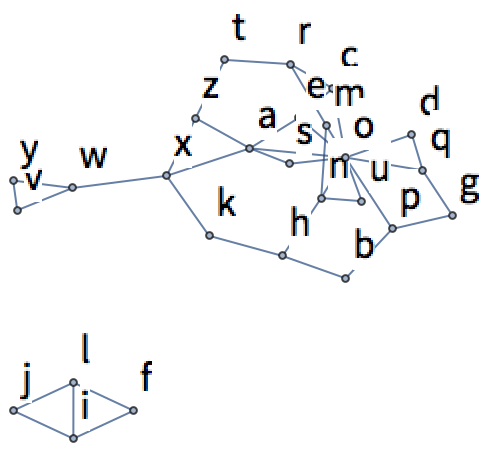
22.14Genere una tabla con los resultados de usar TextRecognize en “hello”, rasterizado en tamaño 50 y con niveles de difuminación entre 1 y 10. »
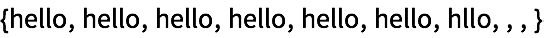
+22.1Construya una tabla de identificaciones de imagen para una foto de la torre Eiffel, con borrosidades del 1 al 5. »

+22.3De los colores en la lista Table[Hue[h], {h, 0, 1, .05}], encuentre los 3 más cercanos al Pink. »

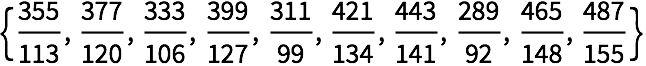
+22.5Genere una lista de 10 números aleatorios del 0 al 10, y hacer un grafo de los 3 vecinos más próximos para cada uno. »


+22.7Haga una imagen del espacio de características para las letras mayúsculas y minúsculas del alfabeto inglés. »

¿Cómo es posible que se obtengan resultados diferentes de los mostrados aquí?
Probablemente, porque las funciones para aprendizaje de máquinas en Wolfram Language cada vez tienen más entrenamiento, lo que hace que los resultados vayan cambiando, y se esperaría que fueran cada vez mejores. En el caso de TextRecognize, los resultados pueden depender del detalle de las fuentes utilizadas y de qué manera se generaron y rasterizaron en la computadora que se esté usando.
Se basa en redes neuronales artificiales inspiradas en la forma como parece funcionar el cerebro. Se le ha entrenado con millones de ejemplos de imágenes, con lo cual ha ido aprendiendo progresivamente a hacer distinciones. Y, de manera parecida al juego de “veinte preguntas”, a base de usar suficientes distinciones puede determinar a qué corresponde una imagen.
Por lo menos 10 000, que es más de lo que puede hacer una persona típica. (En inglés hay alrededor de 5 000 nombres “representables como imagen”.)
Una causa frecuente es que se le pregunte algo que no se parezca a nada para lo que haya recibido entrenamiento. Esto puede pasar si algún objeto se encuentra en una configuración o ambiente poco habitual (por ejemplo, si una embarcación no tiene un trasfondo azulado). ImageIdentify intenta generalmente encontrar algún tipo de coincidencia, y muchas veces los errores que comete son parecidos a los “errores humanos”.
¿Se pueden pedir las probabilidades que ImageIdentify asigna a diferentes identificaciones?
Sí. Por ejemplo, para conocer las probabilidades de las primeras 10 identificaciones en todas las categorías, se usa ImageIdentify[image, All, 10, "Probability"].
Si se trata de un área general que conozca bien (imágenes cotidianas), podrían bastar unas cien. Pero en áreas nuevas, podrían requerirse millones de ejemplos para alcanzar buenos resultados.
Buscando aquellas con la menor EditDistance, esto es, la que requiere menor número de inserciones, eliminaciones y sustituciones de letras individuales.
Absolutamente. El último grafo de esta sección es un ejemplo de eso.
No hay una respuesta sencilla para esta pregunta. Cuando se le presenta una colección de objetos, aprende sus características distintivas; si bien, típicamente, parte de haber visto muchos otros objetos del mismo tipo general (como imágenes).
- Wolfram Language almacena en la nube sus más recientes clasificadores para aprendizaje de máquinas, pero en el caso de que se use un sistema de escritorio, se descargarán automáticamente y correrán localmente.
- BarcodeImage y BarcodeRecognize trabajan con códigos de barras y códigos QR en vez de texto puro.
- ImageIdentify es el núcleo de lo que hace el sitio web imageidentify.com.
- Si solo se dan a Classify ejemplos para entrenamiento, producirá una ClassifierFunction que se puede aplicar posteriormente a muchos tipos de datos diferentes. Es así como casi siempre se usa Classify en la práctica.
- Puede obtenerse un conjunto estándar amplio para entrenamiento con dígitos manuscritos usando ResourceData["MNIST"].
- Classify elige automáticamente entre métodos tales como regresión logística, Bayes ingenuo, bosques aleatorios y máquinas de vectores de soporte, así como redes neuronales.
- FindClusters realiza aprendizaje automático no supervisado, en el que la computadora simplemente revisa los datos sin que se le dé información al respecto. Classify realiza aprendizaje automático supervisado, dado un conjunto de ejemplos de entrenamiento.
- Dendrogram lleva a cabo una formación jerárquica de cúmulos, y puede usarse para reconstruir árboles evolucionarios en áreas como la bioinformática y la lingüística histórica.
- FeatureSpacePlot hace reducción de dimensión, partiendo de datos representados por muchos parámetros, y encontrando alguna buena manera de “proyectarlos” para poder obtener imágenes en 2D.
- Rasterize/@Alphabet[ ] es una mejor forma de rasterizar letras, pero /@ no será tratado hasta la Sección 25.
- FeatureExtraction permite obtener los vectores de características utilizados por FeatureSpacePlot.
- FeatureNearest es como Nearest, excepto que aprende lo que debe considerarse como próximo, examinando los datos mismos que se le den. Esto es lo que se requiere para construir algo como una función de búsqueda de imágenes.
- Uno puede construir y entrenar sus propias redes neuronales en Wolfram Language mediante el uso de funciones como NetChain, NetGraph y NetTrain. NetModel da el acceso a redes preconstruidas.


